异构数据集成的最佳实践
1、什么是异构数据集成
所谓异构数据本质上就是不同的数据源和不同的数据结构,就我们现在的项目业务而言,异构数据主要来源及其结构如下:
- 业务系统产生的业务数据,如日志、订单、用户等;
- 原始空间数据,包括算法或业务产生的
geotif、shapfile、geojson等; - 空间数据服务,包括
wms、wmts、tms等; - 统计聚合类数据,如折线图、饼状图等;
其实上述数据没有完整包含所有项目使用的数据,但是在类型上已经包含了绝大部分业务场景了。在上述的分类情况下异构数据集成的核心显然就是将这些不同来源的数据集成为同一个数据源,然后再对外提供数据服务能力,这便是异构数据的集成。
2、构建异构数据集成方案的必要性
传统的项目执行与进行过程中我们产品团队与项目团队无法将最终程序的共享进行提炼与提纯,导致这种集成框架需要覆盖的业务范围是无限的存在,也是这种情况下几乎无法进行有效的而集成方案建设。但是单纯从技术角度而言我们的项目形态虽多但是产品形态在可视化这个维度几乎已经定性了,存在如下特点:
- 对大量不确定的标准空间数据图层的切换展示;
- 对系统业务数据进行各个维度的聚合统计、分析与图表展示;
- 对不同情况下算法运算的结果进行有效的渲染与展示(地图、图表、报告);
由于系统构成与来源不同,时常会出现同一套系统下的几个子系统存在独立的数据库、独立的设计框架与独立的实施阶段,最终在进行数据分析层建设的时候时常会出现如聚合不同数据库数据进行统计的情况、将数据库数据与第三方接口数据整合统计、将历史老系统部分数据结合当前系统数据整合分析等等这类数据分析需求,面对这样的情况有效的异构数据集成方案是实施后续分析步骤的基础。传统做法是独立为每一个系统开发分析接口再由前端整合,这里无论是产品设计的难度还是前端的沟通成本都是极其巨大的,这边是为什么异构集成实际上对于我们后续项目是非常重要的。
3、异构数据集成的需求
在论证什么是异构数据集成和为啥要做异构数据集成之后,下一个论点自然而然是这个方案我们要做成什么样子,这就是具体的集成需求了,其实理论上来说这里应该是项目和产品提出的,目前产品与项目无法提出可以落地的需求,所以最终集成方案需求还是技术在整理,目前我大致整理集成需求如下:
- 快速集成:能够通过低代码、甚至无代码方案实现获取不同数据库、文本文件、接口等简易数据结构;
- 可拓展性:集成平台需要具备拓展能力以支持
shapfile、geotiff、grib2等专用数据格式; - 数据统一性:集成平台应该将数据集成到同一个数据库(支持空间数据)之中(非结构化除外);
- 数据服务能力:集成之后的数据能够低代码甚至无代码对外提供查询、统计、分析接口,方便前端快速集成;
- 灵活性:数据集成的规则、策略能够快速变更以满足大屏类系统高主观性、高频变更的需要;
上述需求一方面是对数据集成本身的能力要求,主要表现在快速变更上;另一方面则是数据最终怎么去用,不仅仅是入库而已,更需要其具备提供服务的能力,这样一来便可以满足当前的项目需要。
4、异构数据集成的方案设计
4.1、整体说明
目前经过了一系列调研,由于整个调研过程没有协作的需要,也没有产品和项目的配合,所以什么可行性分析、调研报告、技术选型等过程文档全部省略,最终形成设计方案文档即可,加之该文档仅作为技术实施部分的指导设计文档,所以文档最终采用markdown进行git进行版本管理,目前设计架构图如下:
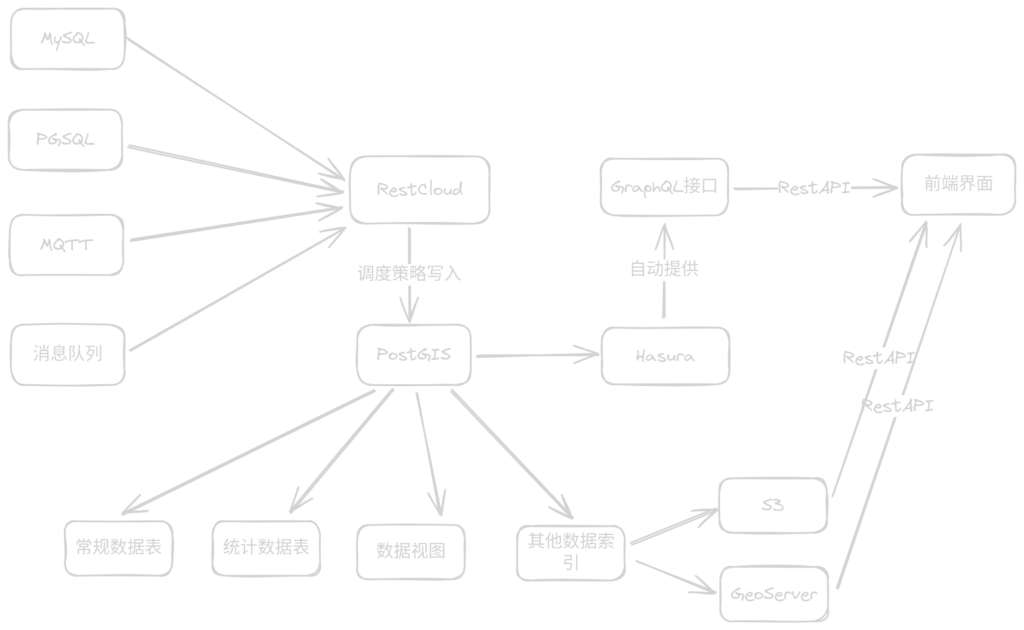
这个图的具体组成主要是:
- 原数据:这里就是原始的数据库数据,包括不限于图里面的
mysql、pgsql等,主要支持关系型数据库、大型数据库、时序数据库、消息队列、第三方API接口五个类别的原始数据; RestCloud:这是一个商用的ETL工具,但是目前是可以完全免费使用,这个工具的存在是为解决上述原始数据源的集成问题,选型上主要考虑的是易用性和可拓展性来看,这是目前调研下来整体表现最好的;PostGIS:这里是作为数据集成之后的汇聚数据库,采用PostGIS一方面是其空间数据支持,另一个维度是信创数据库有8成都是PGSQL换皮,后续如果要求的话,兼容性也不错,同时该汇聚数据库内部数据主要是如下分类:- 常规数据库:原始数据做简单映射和清洗之后全量\增量入库形成的数据;
- 统计数据库:将原属数据按照统计维度进行了预聚合之后形成的聚合数据,主要用于快速查询统计的需要;
- 数据视图:需要负责统计的数据通过后端开发编写
SQL形成的视图数据; - 其他数据索引:这里主要是将文件链接、
geoserver图层链接等信息使用字符串存储到数据库; Hasura:这是一个开源项目工具,其核心作用是自动将PostGIS数据库生成GraphQL的API,这样一来便可以实现前端直接查询数据库而不需要后端编码开发接口;- 前端界面:这就是我们前端开发了,不限于大屏,同时包括小程序、移动段等等需要查询显示数据的地方;
以上对整体框架进行了说明,具体实施上还有细化的规范与使用说明,其中RestCloud的使用和GraphQL的使用需要进一步说明
4.2 、RestCloud的使用说明(后端工作)
RestCloud本质上是一个ETL工具,不同于Kettle、nifi等老牌开源工具,RestCloud的使用更加简单并且符合直觉。虽然该系统是一个闭源的商用系统,但是该系统完全免费使用,并且功能完备。同时因为该步骤仅仅实现的是ETL功能,与整体方案而言是一个可被替换的构件,所以后续如果起其许可出现问题我们也可以顺势将其替换为开源的ETL只不过是使用复杂一些而已,作为初步使用的话,RestCloud刚刚好,官方文档。
部署运行
docker run -d --name=restcloud --restart=always --privileged \
-p 8080:8080 \
-v /data:/data/mongodb/db \
ccr.ccs.tencentyun.com/restcloud/restcloud-etl:V3.7
- 系统部署使用Docker是最简单的方案,这里我之间将Docker的执行命令整理出来即可:
- 容器启动之后进入网页,默认用户名:
admin,密码:pass。 - 激活系统:注册一个
restcloud的账号,然后使用申请激活码获取一个6个月的激活码,然后开始使用系统;
配置数据源
- 没有特别需要说明的,在数据源配置界面直接使用界面配置对于的
jdbc链接便可以完成数据源配置; - 后续在数据应用里面配置流程时直接引用即可;
配置数据流程
- 数据应用直接新建即可,没有什么特别说明;
- 数据流程主要是如下几个节点需要详细说明一下:
- 所有数据的查询与表数据的处理,尽量不要使用原始的表输入节点,而是使用
SQL脚本节点,保证其快速可读性与易修改性; - 数据映射、数据值修改、数据架构修改等等系列操作,尽量不要使用数据转换节点,而是使用
java脚本,同样是保证其快速可读性与易修改性; - 数据输出步骤与上面两个相反,不要使用
SQL脚本,统一使用库表输出,原因在与该节点可以对数据覆盖策略进行控制,同时为了保证结果数据库一致性与可迁移性也应该如此;
- 所有数据的查询与表数据的处理,尽量不要使用原始的表输入节点,而是使用
- 调度上面可以自行配置相关的调度策略,建议经历不使用数据库监听,而是通过定时策略进行;
JAVA脚本说明
execute函数:这是脚本的入口函数,执行java脚本节点本质上就是执行这个函数,无论如何,该函数在没有异常情况下应该返回”1″,其他情况则说明函数执行异常,同时数据流程也会在这个节点中断;java代码需要编译:java代码肯定不是脚本代码,也没有什么脚本引擎,所以单纯保存节点实际上是无法进行代码更新的,应该点击上面的编辑并保存按钮才行indoc参数:这个参数是上一个节点传入到JAVA脚本节点的数据,如果上一个节点为空,则这里啥都没有;- 如何传入下一个节点:虽然可以从
indoc获取上一个节点的数据,但是实际上还是主要使用engine.getData(indoc);获取数据,并且这里返回的List就是输出给下一个节点的数据; - 如何使用第三方lib
- 去对于的仓库下载jar包,比如说
hutools - 将下载好的jar包然后挂载到容器里面
/usr/tomcat/webapps/ROOT/WEB-INF/lib路径 - 在JAVA脚本里面正常import对于的包,然后编写逻辑代码即可,这个方案也可以在JAVA自定义规则里面使用
- 去对于的仓库下载jar包,比如说
示例代码:
public class ETL_T00005_2GJAXHND3UA implements IETLBaseEvent {
@Override
public String execute(IETLBaseProcessEngine engine, Document modelNodeDoc, Document indoc,String fieldId,String params) throws Exception {
// 之间从indoc获取上一个节点传入的数据
List<Document> layerList = indoc.getList("data", Document.class);
// 通过engine获取上一个节点传入的数据
// 同时这个docs也是输出给下一个节点的数据
List<Document> docs = engine.getData(indoc);
// 清空所有数据
docs.clear();
// 向输入添加一个{"xxxx":"xxxx"}
docs.addAll(new Document("xxxx","xxxx"));
// 节点执行成功
return "1";
}
}
输出到目标库说明
- 全量覆盖更新:删除现有目标表的所有数据,然后写入流程执行的数据;
- 增量添加更新:将流程执行的数据添加到目标表后面,这里必须设置一个表的主键,如果主键存在则更新否则插入,这个逻辑输出节点已经实现只需要配置即可
- 是否创建表:如果目标库里面没有表,流程执行数据会根据其自身的结构自动创建表,并且写入,配置即可;
- 数据更新方式:优先选择逐条更新,速度最慢但是一致性最高,其次选择合并后批量(海量条目时选择),最后是批量(尽量不要用);
4.3、Hasura的部署配置说明(后端工作)
Hasura的所有是对我们集成后的目标库自动生成GraphQL的API,这样以来前端要什么数据可以自己去查询而不需要后端疯狂改接口,这个使用就非常简单了,同样使用Docker部署:
docker run -d --name=graphql-engine --restart=always \
-p 8080:8080 \
-e HASURA_GRAPHQL_DATABASE_URL="postgres://username:password@host:port/dbname" \
-e HASURA_GRAPHQL_ENABLE_CONSOLE=true \
hasura/graphql-engine:v2.45.1-ce
启动之后直接浏览器打开即可,如果是生成环境建议是关闭HASURA_GRAPHQL_ENABLE_CONSOLE便没有网页界面了,这个界面其实主要就三个作用:
- 快速预览数据;
- 使用工具生成
GraphSQL请求体; - 创建接口(这个几乎没有什么用);
所以一旦我们的代码编写完毕之后其实是不需要这个界面的,同时由于该容器最终的持久化数据其实是在连接的数据库里面说明容器运行配置没有必要映射持久卷,官方文档
4.4、GraphSQL的使用(前端工作)
GraphSQL是一个标准,当今世界有很多系统系统为了提升前后端的内聚程度,形成的一种运行时架构风格的工具,与之对标的标准就是RestfulAPI,相较于而言GraphSQL更加强调运行时的灵活性,这种灵活性虽然导致了一定程度上数据权限的溢出,在可控性上有所降低,但是对于我们所谓的可视化常见的绝大部分情况都是非常好用的,如果要系统性的学习GraphSQL先使用可以去看官网的说明文档,这里我将我们最常用的查询列举说明一下:
查询特定字段
// query 说明这是一个查询
// get_logs 是查询的名称,这里是完全自定义的可以是任何名字
query get_logs {
// sys_log_operate 说明查询的是sys_log_operate这张表或视图
sys_log_operate {
// 这里是查询表或视图里面的这些字段
id
browser
created_by
created_date
description
}
}
查询条件
query get_logs {
// 添加一个条件,查询id字段等于"xxxxxx"的数据
sys_log_operate(where: {id: {_eq: "xxxxxx"}}){
id
browser
created_by
created_date
description
}
}
// 除此之外还有
sys_log_operate(where: {
// 创建时间大于"2024-12-10"
created_date: {_gt: "2024-12-10"}},
// 创建时间小于"2024-12-12"
created_date: {_lt: "2024-12-12"}},
// 创建时间大于等于"2024-12-10",同时小于等于"2024-12-12"
created_date: {_gte: "2024-12-10", _lte: "2024-12-12"}},
// 字符串模糊查询,browser包含MS的结果
browser: {_like: "%MS%"}
// 正则查询,browser包含edge字符的结果
browser: {_iregex: "(?i)edge"}
})
分页查询
query get_logs{
// limit: 10,限制每一页为10条
// offset: 10,从第十条还是查询,也就是第二页,所以:offset = ( 页数 - 1 )* limit
sys_log_operate(limit: 10, offset: 10) {
id
browser
created_by
created_date
description
}
}
排序查询
query get_logs {
// 时间增序
sys_log_operate(order_by: {created_date: asc}) {
id
browser
created_by
created_date
description
}
}
query get_logs {
// 时间降序
sys_log_operate(order_by: {created_date: desc}) {
id
browser
created_by
created_date
description
}
}
聚合查询
这种情况比较特殊,无法仅仅通过graphql实现,但是可以让后端在数据库创建视图,然后前端直接查询视图即可,这种方案也非常灵活,并且后端无需编码;
空间查询
// 没错这个东西是支持空间查询的
query get_logs {
// 查询目标字段在某个范围内,这里只支持geojson,geom字段是SRID=4326的geometry类型
geometries(where: {geom: {_st_within: "{\"type\":\"Polygon\",\"coordinates\":[[[0,0],[130,0],[130,60],[0,0]]]}"}}) {
name
geom
}
}
其他剩余支持的空间查询字段:
- _st_within:判断一个几何对象是否完全包含在另一个几何对象内。
- _st_contains:与_st_within相反,判断一个几何对象是否完全包含另一个几何对象(传入的几何体)。
- _st_crosses: 判断两个几何对象是否相交。
- _st_intersects: 判断两个几何对象是否有任何公共部分。
- _st_touches:判断两个几何对象是否只在边界处接触,没有重叠的部分。
- _st_overlaps:判断两个几何对象是否相交,且交集是一个与两者不同但维度相同的几何图形。
5、总结
表面上来看前端开发可能会觉得,大部分数据查询逻辑的编写全部交给前端写了了,这样增加了前端工作量。但是我必须再次强调GraphSQL是当前一种现行标准,和Restful API一样是被广泛接受并且大面积使用的一种标准,如果你不晓得也正常,常规业务系统由于强权限的需要也的确不会突出的使用GraphSQL作为主要方案,但是对于分析数据,特别是已经有独立的分析数据库情况下,GraphSQL就是标准答案,虽然算不上银弹,但是也是这种场景下开发效率上的最优解。所以对其不要抗拒,当前绝大部分新型数据原始的控制方案就提供了GraphSQL接口,学无止境,对前端而言系统性学习使用GraphSQL也是时代发展的必然的。最后还有一个点,前端虽然做了数据查询工作,但是这个数据的构成还是由后端组织的,你难道不觉得很多时候调整增加一个字段需要等待后端搞接口发版本是一个很SB的事情吗?这下好了,数据库自己搞定之后你们想要什么自己去拿,它难道不方便吗?