低成本的数据备份方案
各位试想这么一个场景,你买了一个VPS服务器,高高兴兴的搭建了一个博客,本来运行的好好的,但是VPS服务商突然跑路了(或者它机房起火了),这种事情对于我们这种购买便宜的VPS的个人用户而言不能说随处可见,也可以算的上是稀松平常了。你问我为啥不买阿里云这种靠谱的云平台?哥们,最便宜的阿里云轻量云服务器也要24块一个月,你有见过24块一年的云服务器吗?所以抛开价格说安全都是耍流氓。并且像博客这种系统它不仅仅是文件的备份,起码还有一个数据库吧?加上博客是一个典型的增量业务类型,我们需要一个备份方案能够实现对复杂数据的多维数据进行全量和增量备份,没错,这比备份照片这种场景复杂多了。
然后看到这个标题很多朋友肯定疑惑了,上一篇博文里面你不是都自建NAS和Homelab吗?直接将数据备份到NAS上不就行了吗?道理是这样没有错,但是真正安全与高效的备份应该符合3-2-1原则,及一共三分完整数据、分布在两种不同的存储介质、其中有一份数据在异地。我也算是常年和数据打交道了,正经在工作之中的备份方案都有专业的服务商提供安全高冗余的存储方案,比如说阿里云提供的低频对象存储等。这样的方案好是好,并且安全性极高,问题就是太TM贵了,表面上看但论存储空间倒是和网盘一个价格,但是你不要忘了,对象存储服务的流量、操作请求等等都需要单独计费,整体算下来其实不便宜。在企业里面为了那无价的数据安全,花点钱其实对于企业主而言没有什么不可,但是对于我们这种个人用户而言就非常难受了。
对于我们这种垃圾佬而言,下面这些要求不过分吧?
-
既要能够实现复杂系统的增量备份
-
又要符合3-2-1原则,给我们提供真正意义上的安全备份
-
还要做到低成本,最好是不要钱。
没错就是既要又要还要,看到这篇文章的你有福了,本文将会给你一个完全免费的方案做到上述的一切。
备份的神器Restic——解决复杂文件系统备份问题
Restic工具是一个自带快照的备份工具,不仅仅可以实现增量备份、取消存储冗余、压缩备份,同时在备份过程中可以实现对文件权限、软连接等等属性的全量保存,最关键的是对海量小文件在备份时候会被整合为固定大小的块进行存储,所以无论原始文件是什么样子,最终备份后的文件是一堆特定大小的块的文件。
这样的特性使得这个东西非常适合云备份和迁移海量小文件的,一方面特定大小的块包装最终输出的文件的数量既不会特别大,也不会特别多;
具体的操作方案如下:
安装Restic
这里我以RHEL兼容版本AlmaLinux为例(比如Centos或RockLinux也是一样的)
1
2
3
yum install epel-release
yum install restic
初始化仓库
初始化一个备份的目标仓库,这里要求输入一个密码作为仓库的访问控制:
1
restic --repo /backup init
也可以将密码设置为环境变量,那么初始化时就不要求输入了
1
RESTIC_PASSWORD=password
也可以把仓库设置在环境变量里面
1
RESTIC_REPOSITORY=/backup
仓库可以选择很多不同的类型,上面是本地仓库,除此之外还有:
1
2
3
4
5
6
7
8
9
10
11
12
# sftp
restic -r sftp:user@host:/srv/restic-repo init
# rest server
# 注意这个rest不是你随便高个http服务就行,他是有一定规范的,可以参考这个项目:
# https://github.com/restic/rest-server
restic -r rest:http://host:8000/ init
# s3对象存储,此时需要称传递AK环境变量授权:AWS_ACCESS_KEY_ID,AWS_SECRET_ACCESS_KEY
restic -r s3:https://s3.us-east-1.amazonaws.com/bucket_name init
# 如果是http协议的本地连接则使用http即可,比如:
restic -r s3:http://192.168.0.8:5426/bucket_name init
初次之外还有什么谷歌云硬盘、微软块存储服务、openstrck等等这些云平台,我们垃圾佬肯定用不起,这里就不展开说了
操作仓库备份
一旦初始化完成之后就是备份操作,假设仓库信息和密码都是通过环境变量设置好了
1
2
3
4
5
6
7
8
9
10
# 备份/data目录
restic backup /data
# 备份多个目录
restic backup /data1 /data2
# 给备份添加tag
restic backup --tag xxx /data
# ps: 备份可以使用一系列的flag进行控制,比如说排除某些文件,但是这种不常用这里就不提了
快照管理
每一次成功执行了一个备份之后都会形成一个快照,后续的备份就是对前一个快照的增量备份
1
2
3
4
5
# 查询所有快照
restic snapshots
# 查询具体tag、host、path的快照
restic snapshots --tag xxx --host xxx --path="/data"
同时可以删除快照
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# 移除快照
restic forget 快照ID
# 仅仅移除快照后原始的文件其实还在,执行prune清除没有被引用的文件
restic prune
# 或者同时清除与移除
restic forget 快照ID -prune
# 可以使用规则批量删除快照,保留最近10次快照
restic forget --keep-last 10 --prune
# 当然也可以通过tag、host、path制定删除的范围
restic forget --keep-last 10 --prune --tag xxx --host xxx --path="/data"
恢复数据
恢复数据需要用快照ID进行恢复
1
2
# 恢复文件至指定的路径,注意:如果你的快照是/data,最终恢复的路径应该是:/tmp/restore-work/data
restic restore 快照ID --target /tmp/restore-work
当然也可以使用最新的快照进行恢复
1
2
# 同时也可以用path和tag进行过滤
restic restore latest --target /tmp/restore-work --path "/data" --host xxx
对象存储——快速异构集成与完美可用性
上面的restic最终备份得到的文件是什么?是一堆大小一致的块文件,也就是说,你的原始文件可能数量巨大但是体积很小,会消耗海量的对象存储http请求,如果你使用restic进行备份(将restic仓库直接设置到对象存储)你最终发送到对象存储服务器的数据其实是转换之后的块文件,同时解决了请求数量与备份性能的问题。加之对象存储服务本身如果是靠谱的供应商提供的,那么我们可以认为他就是最好的备份存储服务,为啥呢?理由如下:
-
对象存储S3具备很高的通用性,无论你是什么终端(甚至无终端)都可以使用http去实现S3协议以完成数据操作;
-
对象存储本身是平台无关的,无论你是windows系统还是linux,无论你是C++还是Java都可以快速集成S3作为存储;
-
对象存储的社区认同度很高,几乎所有存储相关的开源项目都会实现S3的API导致几乎大部分SelfHost服务都可以快速集成对象存储;
同时对象存储又是在绝大部分云平台都提供对应的服务,而且各个平台都是按照什么99.995 %可用性宣传的,事实上即使是企业应用,各家平台的对象存储服务也是归档数据云备份的首选。不过对于我们这种家里自建服务器或者VPS数据备份的用户而言,其实直接购买云平台的对象存储服务显得性价比很低,我拿阿里云对象存储给大家算一个账:
-
100G的存储空间价格:126块/年
-
100G的下行流量价格:295块/年
-
1000万次请求:10块/年
这三个资源包就是最便宜的阿里云套餐,综合下来就是431块/年,当然这个是标准存储价格。如果低频次包和归档存储更加便宜,如果你用量非常小其实也可以实时计费应该价格会低上更多。但是,别忘了我文章一开始提到的,我的VPS都才24块一年,你这个备份服务的价格是我VPS的20倍,哪怕你打个一折,我都没法接受备份比我服务还贵的情况。所以如果只是给大家介绍阿里云作为对象存储,那简直是对不对看我博客的朋友,我必须找到更加便宜的,最好是免费可靠的对象存储给大家。
赛博菩萨——Cloudflare R2对象存储
没有错,我找到了一个对于个人用户轻量级使用几乎完全免费的对象存储服务,而且Cloudflare来存储你的数据,我相信不少人和我一样甚至认为他比阿里云还要靠谱。其实Cloudflare提供的这个R2对象存储服务也不是完全免费的,他的个人用户使用限制如下:
-
个人用户免费使用10G空间
-
操作计费,A类每月免费100万次,B类每月免费1000万次
-
无限流量(无论上下行)
其中最主要的是,无限流量,意思是无论上下行流量,统统免费,对于我们备份这种场景来讲哪怕你每小时备份/恢复一次你的博客都没有问题。而且在使用restic的基础上,整合碎片文件为块文件,这样以来操作计费完全足够你使用了(A类操作大体就是修改、新增文件;B类操作大概就是删除、下载文件)。最终你的博客加上数据库经过restic压缩之后也不可能超过10G吧,我自己的这个博客实际备份到R2对象存储(10个快照)的空间不到500M,这么来看其实这10G可以备份不少东西了。具体这个东西如何注册、登陆、创建按照Cloudflare的界面直接操作就像行,我的读者肯定都能够自行完成注册创建申请。By the way,如何你不知道如何注册Cloudflare,那赶紧关闭博客,我这些博文不适合你。
各位,是不是很完美?但是,如果你和我一样,个人跑的服务实在是太多了,什么图库、笔记、GIT等等一系列服务都在本地跑的情况下,10G的空间就完全不够看了。如果是大量数据需要备份的情况下,有没有什么免费的可以给我们用呢?之前看过我博客的朋友可能清楚,如果仅仅是到这里,其实还不值得我写一篇博文的,大量数据备份也有办法,大家接着看。
消费级网盘如何变废为宝
相信大家都知道,像什么百度网盘、腾讯网盘、阿里网盘你注册了之后或多或少都会送你一些免费的存储空间,甚至他们都没有什么请求数量和流量的限制,无非就是限速而已。如果这些东西你要是拿来做网盘,那实在是过于垃圾了,几乎没法用。但是如果说你拿它来做备份,就非常合适。但是厂商其实也怕你白嫖他们的存储空间做备份,所有他们都有一个统一的问题,都不提供S3 API,这就导致我们没有办法使用这些网盘作为备份存储使用,如果要手动自行上传那太麻烦了,并且这些网盘几乎都没有提供Linux客户端,所以基本上没法用对吧?那么假设我告诉你,在我们开源世界存在这么一个免费的工具,它可以对外部提供S3 API,并且在底层使用这些消费级网盘作为它自己的存储空间,这样的话,是不是问题就得到了完美的解决?下面隆重介绍:Alist


我在图里面虽然只画了几个各位常用的云盘,但是实际上,Alist几乎支持市面上几乎所有面向个人的消费级网盘,支持清单各位可以自行查看。这里有一个加大白嫖力度的方法,因为Alist的每一种云盘可不只是挂一个而已,比如说谷歌云盘你注册一个账户就有15G的免费空间,如果你有100个谷歌账号是不是就有1.5T的对象存储空间了?其实确实是可以这样操作,只要你没有下限不怕被封号这样确实也可以🤣🤣🤣。这样以来我们就可以通过Alist提供的对象存储服务,使用restic将我们自己的数据备份几乎无限的网盘里面。因为我个人是有365订阅的,所以自然而然使用的微软的Onedrive,我用了很多年的onedirve,从来没有丢过任何数据,非常稳的存储,实力推荐。
如何部署Alist?
这里我就默认大家都和我一样是有NAS或者自建Homelab或者是VPS用户了,如果你用windows那么自己查文档吧(很简单)。部署最简单的方法肯定是用Docker,我也推荐大家都使用Docker,它可以在绝大部分环境运行并且迁移与配置都非常简单,具体的步骤如下:
创建Alist容器,使用如下的启动命令(自行修改端口、挂载路径等):
1
2
3
4
5
6
7
8
9
docker run -d --name=alist --restart=unless-stopped \
-p 5244:5244 \ # Alist 网页端口
-p 5246:5246 \ # Alist S3 API 端口
-e PUID=0 \
-e PGID=0 \
-e UMASK=022 \
-e TZ=Asia/Shanghai \
-v /data:/opt/alist/data \
xhofe/alist
或者用docker compose
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
version: '3.3'
services:
alist:
image: 'xhofe/alist:latest'
container_name: alist
volumes:
- '/data:/opt/alist/data'
ports:
- '5244:5244'
- '5246:5246'
environment:
- PUID=0
- PGID=0
- UMASK=022
- TZ=Asia/Shanghai
restart: unless-stopped
启动容器之后等待进入到你的挂载卷,找到对象存储的配置(容器内部的:/opt/alist/data/config.json)并且修改为启用即可
1
2
3
4
5
"s3": {
"enable": true,
"port": 5246,
"ssl": false
}
然后重启容器即可;
接下来就是配置Alist的存储,也就是我们的网盘了,这里的步骤不同网盘完全不一样,但是这些操作都不涉及到命令行和配置文件,全部都是通过Alist的网页进行操作,这里大家看看官方文档跟着操作就行了,只有一个地方各位稍微注意一下,创建网盘的时候有一个选项是缓冲时间,最好设置为0,以免出现本地数据与网盘不一致的情况;
最后就是对象存储了,在网页的管理里面找到对象存储界面,各位只需要点击生成创建出S3的AK对,然后点击添加将bucket指向具体的路径即可:
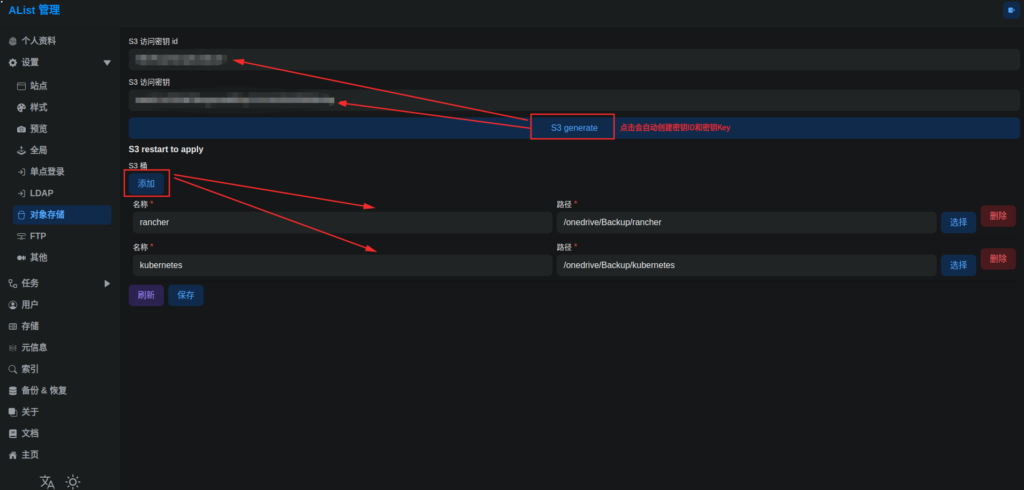
最后各位通过restic配置好S3的地址、AK对、Bucket就可以实现备份到目标网盘,整套方案完全免费,并且几乎可以说是无限的存储空间。
最佳实践
到这里大家都应该知道了,我建议是在你的服务器上编写一个备份的脚本,然后使用crontab定时执行以完成备份操作,我这里举一个例子:
1
2
3
4
5
6
7
8
9
10
11
#!/bin/sh
# 假设你设置好了环境变量,主要是下面这些:
# RESTIC_PASSWORD=${你的密码}
# RESTIC_REPOSITORY=http://${alist地址}:${alist的s3端口}/${alist的s3 bucket也就是桶}
# AWS_ACCESS_KEY_ID=${s3访问密钥id}
# AWS_SECRET_ACCESS_KEY=${s3访问密钥}
# 同时备份/wordpress /mysql两个路径
restic backup /wordpress /mysql
# 只保留10个快照,删除10各以前的
restic forget --keep-last 10 --prune
随便起个名字比如说叫做back.sh,扔到任意路径里面比如说/back.sh,记着给执行权限:chmod +x /back.sh ,然后配置定时执行即可:
1
2
3
4
5
# 编辑定时任务
crontab -e
# 随便给一个定时策略,比如说每天凌晨5点执行
0 5 * * * /back.sh
为啥需要将执行命令作为脚本呢?因为我们在备份前可能会执行一些操作,比如说备份数据库之前应该先让数据库进入只读模式或者暂停数据库,然后在备份完成之后恢复;亦或者通过mysqldump导出sql文件,然后备份这个sql文件即可。具体这些操作需要干什么各位就根据自己的业务自行搞定了。
总结
我自己是这么总结的:数据安全无价(因为没了就真没了)、数据安全也有价(花钱买服务即可)、我选择不要钱的(垃圾佬的觉悟)。所以这套方案,让所有垃圾佬有免费的企业级备份方案可以用,我就问你NB不NB?