基于K8S搭建Ceph分部署存储
版本依赖
搭建思路
很多高级运维人员都2020年了对于K8S的存储大部分都是采用主机路径大法这样的系统搭建简单但是极其不科学,运维者自己也清楚但是为什么不直接搭一套Ceph呢,那就是在系统上搭建Ceph太TM复杂了,我看了整个文档之后也是头皮发麻的。
首先我们不是直接在虚拟机或者物理上直接搭建Ceph,那样的话……,而且当前各路大神的集群思路都是容器化,所以在已有的K8S集群上再搭建Ceph就非常合理,重要的是我们最终只需要通过K8S就可以维护整个集群状态不需要再shell到服务器上各种操作,不光是开发而且就连运维都是一个Serverless状态,多么的帅气是吧,所以我们的思路就是一个:全面容器化。
为何搭建
首先K8S必须要有分部署存储,如果没有的话根本算不上集群,如果不理解这一步那需要去回炉学习一下K8S才行。
其次是我其实已经搭建了一套基于GlusterFS署存储系统,但是这套方案不是容器运行的维护的时候需要我shell到服务器上这就已经很蛋疼了,同时有一个致命的缺陷那就是GlusterFS会建立一大堆TCP链接几乎上万级别在长时间运行之后(大概一个多月左右)存储说挂就挂了而且没法自动恢复,稳定性有点捉急。
但是Ceph不一样,假设K8S是油条那么Ceph就是豆浆,基本上都是一个通识了,核心原因是它能够提供非常稳定的块存储系统,并且K8S对Ceph放出了完整的生态,几乎可以说是全面兼容。
搭建前提
前提比较清楚首先需要如下东西:
- 正常运行的多节点K8S集群,可以是两个节点也可以是更多。
- 每一个节点需要一个没有被分区的硬盘,最好大小一致不然会浪费。
没错其实就是一个要求,必须有集群才能进行容器管理,必须有硬盘才能做存储这些都是基础。
搭建流程
什么是rook
终于到流程了,这里我还是需要先说一下我们搭建Ceph为了最简单的实现也不是手动拉取各种镜像然后配置这样的话和在物理机上搭建没有什么区别,既然已经在K8S上运行了那么我们其实可以通过ROOK自动帮我们进行分部署存储的创建,那么问题来了什么ROOK?
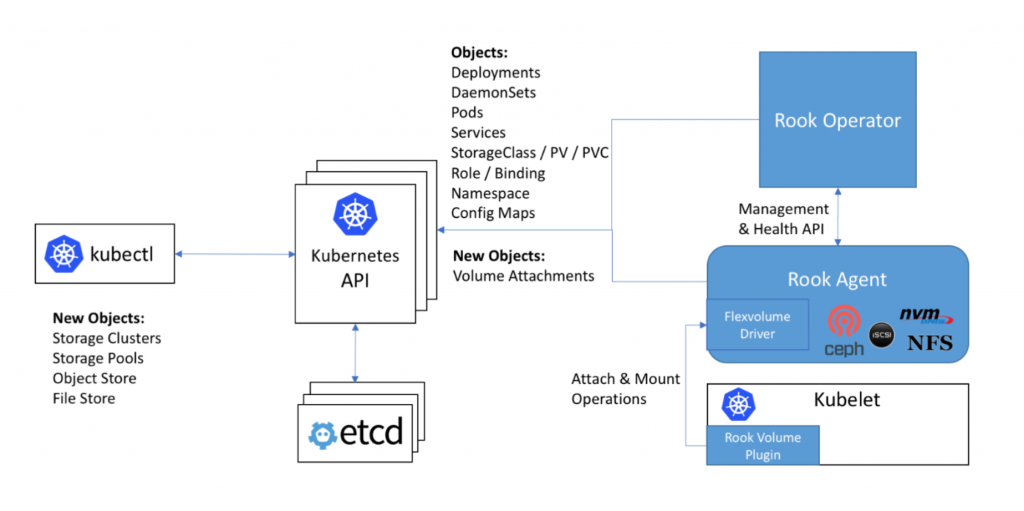
- Rook 是一个开源的cloud-native storage编排, 提供平台和框架;为各种存储解决方案提供平台、框架和支持,以便与云原生环境本地集成。
- Rook 将存储软件转变为自我管理、自我扩展和自我修复的存储服务,它通过自动化部署、引导、配置、置备、扩展、升级、迁移、灾难恢复、监控和资源管理来实现此目的。
- Rook 使用底层云本机容器管理、调度和编排平台提供的工具来实现它自身的功能。
- Rook 目前支持Ceph、NFS、Minio Object Store和CockroachDB。
- Rook使用Kubernetes原语使Ceph存储系统能够在Kubernetes上运行。
所以在ROOK的帮助之下我们甚至可以做到一键编排部署Ceph,同时部署结束之后的运维工作ROOK也会介入自动进行实现对存储拓展,即便是集群出现了问题ROOK也能在一定程度上保证存储的高可用性,绝大多数情况之下甚至不需要Ceph的运维知识都可以正常使用。
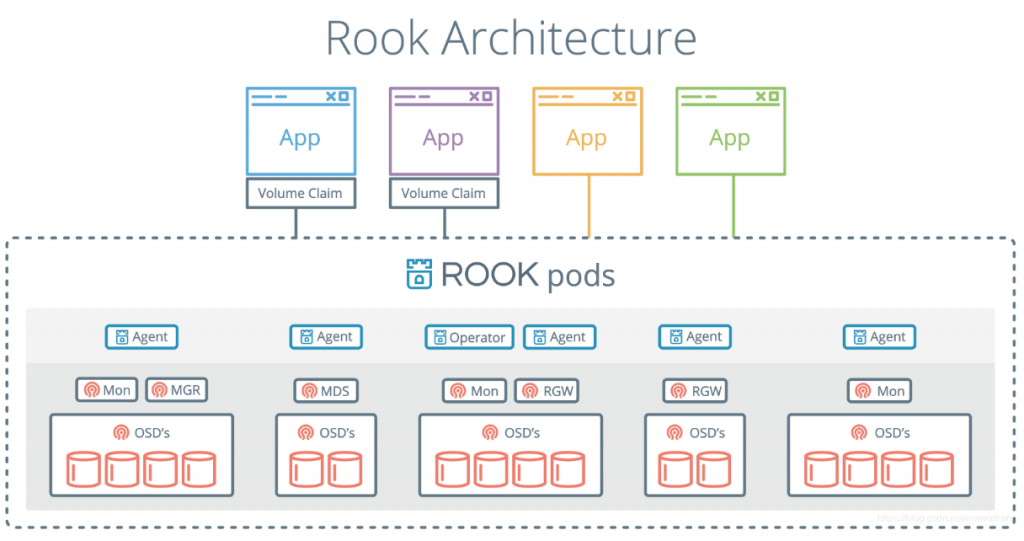
既然已经引入了ROOK那么后面的部署步骤就简单了很多可以参考:ROOK官方文档。
首先便是获取rook仓库:https://github.com/rook/rook.git
安装常规资源
首先在rook仓库之中的cluster/examples/kubernetes/ceph/common.yaml 文件,这个文件是K8S的编排文件直接便可以使用K8S命令将文件之中编排的资源全部安装到集群之中,需要注意的只有一点,如果你想讲rook和对应的ceph容器全部安装到一个特定的项目之中去,那么建议优先创建项目和命名空间,common文件资源会自动创建一个叫做rook-ceph的命名空间,后续所以的资源与容器都会安装到这里面去。运行yaml文件部署常规资源:
#运行common.yaml文件 kubectl create -f common.yaml
安装操作器
操作器是整个ROOK的核心,后续的集群创建、自动编排、拓展等等功能全部是在操作器的基础之上实现的,操作器具备主机权限能够监控服务所依赖的容器运行情况和主机的硬盘变更情况,相当于大脑,编排文件为/cluster/examples/kubernetes/ceph/operator.yaml 这里没有什么需要注意的直接运行安装即可:
#运行operator.yaml文件 kubectl create -f operator.yaml
安装完成之后需要等待所有的操作器正常运行之后才能继续还是ceph分部署集群的安装:
#获取命名空间下运行的pod,等待所以的pod都是running状态之后继续下一步 kubectl -n rook-ceph get pod
创建Ceph集群
这里就厉害了,直接通过一个yaml编排文件能够对整个Ceph组件部署、硬盘配置、集群配置等一系列操作,仅仅这一步便完成了集群的搭建。编排文件为/cluster/examples/kubernetes/ceph/cluster.yaml 但是这里也需要进行一定的基础配置与修改才能继续,cluster.yaml文件内容如下:
apiVersion: ceph.rook.io/v1
kind: CephCluster
metadata:
name: rook-ceph
namespace: rook-ceph
spec:
cephVersion:
image: ceph/ceph:v14.2.6
allowUnsupported: false
dataDirHostPath: /var/lib/rook
skipUpgradeChecks: false
continueUpgradeAfterChecksEvenIfNotHealthy: false
mon:
#这里是最重要的,mon是存储集群的监控器,我们K8S里面有多少主机这里的就必须使用多少个mon
count: 3
allowMultiplePerNode: false
dashboard:
#这里是是否启用监控面板,基本上都会使用
enabled: true
#监控面板是否使用SSL,如果是使用8443端口,不是则使用7000端口,由于这是运维人员使用建议不启用
ssl: true
monitoring:
enabled: false
rulesNamespace: rook-ceph
network:
hostNetwork: false
rbdMirroring:
workers: 0
crashCollector:
disable: false
annotations:
resources:
removeOSDsIfOutAndSafeToRemove: false
storage:
useAllNodes: true
useAllDevices: true
config:
disruptionManagement:
managePodBudgets: false
osdMaintenanceTimeout: 30
manageMachineDisruptionBudgets: false
machineDisruptionBudgetNamespace: openshift-machine-api
相同的直接通过编排指令部署集群:
#运行cluster.yaml文件 kubectl create -f cluster.yaml
创建监控面板
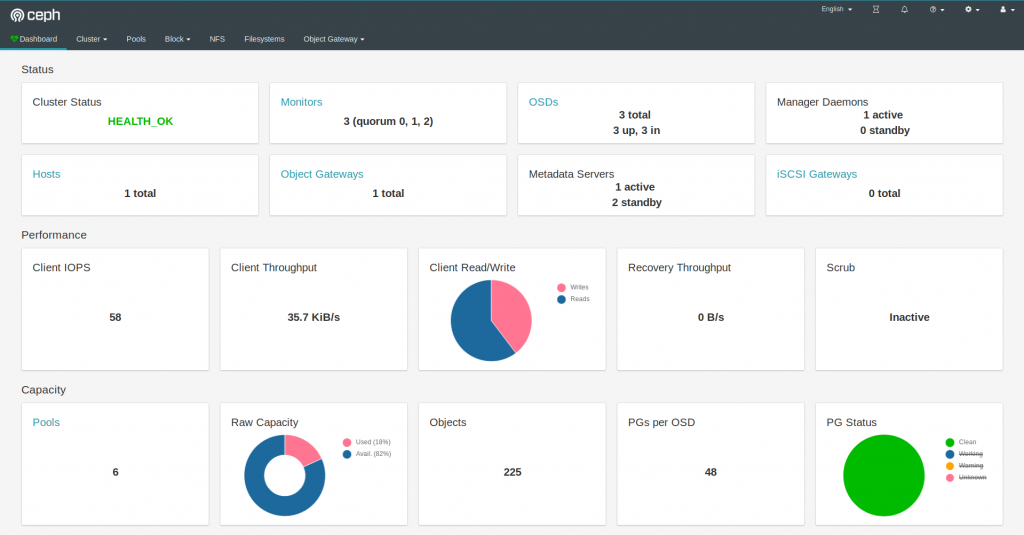
也是一个yaml编排文件能够通过集群将dashboard端口给服务出来,也是一句编排指令,如果上面启用了SSL则需要使用/cluster/examples/kubernetes/ceph/dashboard-external-https.yaml否则使用同目录下的dashboard-external-http.yaml文件:
#dashboard没有启用SSL kubectl create -f dashboard-external-http.yaml #dashboard启用SSL kubectl create -f dashboard-external-https.yaml
创建Ceph工具
正式环境运维绝大部分问题Rook都能购自动解决但是一旦出现无法解决的情况便需要手动对Ceph进行配置操作了,所以需要Ceph工具,他也是一个容器,运维人员可以直接通过对这个容器的shell进行Ceph集群的控制(后面有实例),编排文件是toolbox.yaml:
#安装Ceph工具 kubectl create -f toolbox.yaml
创建存储系统与存储类
集群搭建完毕之后便是存储的创建,目前Ceph支持块存储、文件系统存储、对象存储三种方案,K8S官方对接的存储方案是块存储,他也是比较稳定的方案,但是块存储目前不支持多主机读写;文件系统存储是支持多主机存储的性能也不错;对象存储系统IO性能太差不考虑,所以可以根据要求自行决定。
存储系统创建完成之后对这个系统添加一个存储类之后整个集群才能通过K8S的存储类直接使用Ceph存储。
块存储系统+块存储类yaml文件:
apiVersion: ceph.rook.io/v1
kind: CephBlockPool
metadata:
name: replicapool
namespace: rook-ceph
spec:
failureDomain: host
replicated:
size: 3 #这里的数字分部署数量,一样有几台主机便写入对应的值
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-ceph-block
provisioner: rook-ceph.rbd.csi.ceph.com
parameters:
clusterID: rook-ceph
pool: replicapool
imageFormat: "2"
imageFeatures: layering
csi.storage.k8s.io/provisioner-secret-name: rook-csi-rbd-provisioner
csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph
csi.storage.k8s.io/node-stage-secret-name: rook-csi-rbd-node
csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph
csi.storage.k8s.io/fstype: xfs
reclaimPolicy: Delete
文件系统存储yaml文件:
apiVersion: ceph.rook.io/v1
kind: CephFilesystem
metadata:
name: myfs
namespace: rook-ceph
spec:
metadataPool:
replicated:
size: 3 #这里的数字分部署数量,一样有几台主机便写入对应的值
dataPools:
- replicated:
size: 3 #这里的数字分部署数量,一样有几台主机便写入对应的值
preservePoolsOnDelete: true
metadataServer:
activeCount: 1
activeStandby: true
文件系统存储类yaml文件:
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: csi-cephfs provisioner: rook-ceph.cephfs.csi.ceph.com parameters: clusterID: rook-ceph fsName: myfs pool: myfs-data0 csi.storage.k8s.io/provisioner-secret-name: rook-csi-cephfs-provisioner csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph csi.storage.k8s.io/node-stage-secret-name: rook-csi-cephfs-node csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph reclaimPolicy: Delete
问题解决
正常按照上述流程之后或多或少集群状态可能有点问题我这里将我遇到的问题统一说一下并且提供其对应的解决方案:
PG数量不足:
这个问题是创建存储系统时的存储池时没有给每一个池足够的PG所以导致的存储集群警告修复也比较容易可以通过Ceph工具运行Ceph命令进行配置:
#获取Ceph系统之中池的列表 ceph osd pool ls #设置一个池的PG数量 ceph osd pool set 池名称 pg_num 池数量
OSDs数量不足三个
这个问题出现的原因是在创建Ceph集群的时候由于只有两台主机所以只是用了两个MON导致的,这里也比较容易进行修改,可用通过rook-config-override映射重新配置Ceph从而解决这个警告:
#修改Ceph配置
kubectl -n rook-ceph edit configmap rook-config-override -o yaml
#自动打开对应的yaml文本
apiVersion: v1
data:
config: |
[global] #添加全局自定义配置
osd pool default size = 2 #配置osd默认数量为2
kind: ConfigMap
metadata:
creationTimestamp: 2018-12-03T05:34:58Z
name: rook-config-override
namespace: rook-ceph
ownerReferences:
- apiVersion: v1beta1
blockOwnerDeletion: true
kind: Cluster
name: rook-ceph
uid: 229e7106-f6bd-11e8-bec3-6c92bf2db856
resourceVersion: "40803738"
selfLink: /api/v1/namespaces/rook-ceph/configmaps/rook-config-override
uid: 2c489850-f6bd-11e8-bec3-6c92bf2db856
OSD无法找到集群控制器导致无法启动服务
OSD服务本质上就是对一个硬盘的控制服务,每一次对OSD重新部署需要兼顾同一个版本,如果出现这个问题说明上层控制版本与OSD版本不一致,通过对集群的operator操作器进行重启便可以实现对整体版本的更新从而保证硬盘OSD能够正常启动。首先重新部署OSD使其处于故障状态,其次重启operator他会寻找异常OSD并且从链路上重新启动。
OSD无法找到逻辑卷导致无法启动服务
OSD服务需要依靠之前建立的逻辑卷才能启动这一步是在OSD核心服务启动之前完成的,出现这个问题是由于宿主机没有安装LVM2(逻辑卷管理器)导致的,通过对LVM2组件的安装之后重启节点服务器便可以使其恢复正常。重启服务器还是有一定的风险确定备份与容错手段全部建立完毕之后再执行。
OSD服务内存泄露问题
一旦发生数据重建或者数据移动的时候各个相关节点的OSD服务占用内存会增加,最终导致集群节点失效死锁的情况,目前不知道如何解决这个问题,内存增长的过程比较缓慢,目前只能长期监控,当内存达到一个峰值之后手动重启,有谁知道这个东西怎么解决的话告诉我一声。
硬盘识别不到或者硬盘已经加入LVM
这个问题足足搞了我一天的时间,一点点式出来的。找不到硬盘的原因是硬盘已经经过分区了,但是如果你将一个硬盘的分区删除之后有会爆出硬盘已经加入LVM组的错误,这个问题也是对Linux卷系统了解不足导致的,解决方案就是将逻辑卷组删除即可,在硬盘无分区的情况下:
#查看逻辑卷情况 lsblk #删除逻辑卷/dev/vg0/lv0 lvremove /dev/vg0/lv0 #查看逻辑卷组 vgs #删除逻辑卷组vg0 vgremove vg0
总结
终于摆脱了掉GlusterFS存储卷失效的噩梦,晚上可以安心睡觉了。
是怎样去确定osd是用哪盘?
我看你安装时说,需要一块没有分区的盘,但是在后来的步骤中,却没见到哪里说这个盘的使用。可以解一下疑惑吗?
Ceph可以自动识别空闲的盘加入到pool里面,只需要保证盘可用即可。
但是现在我不推荐ceph了,可以试试Rancher出品的Longhorn,简单快捷
kubernetes.io/csi: attacher.MountDevice failed to create newCsiDriverClient: driver name rook-ceph.rbd.csi.ceph.com not found in the list of registered CSI drivers遇到过吗?方便加个QQ联系吗?625503846
有什么需要讨论的就在这里吧,大家也可以看看。
你需要告诉我你是在执行哪个步骤遇到的这个问题,单从日志上来看我估计是你没有完全创建好RDB存储系统或者存储类
我也是卡在这个步骤,就是使用rook-ceph-block创建PVC成功,但是在pod里面启动自动挂载时报出这个错误。
Warning FailedMount 4m25s (x35 over 59m) kubelet, k-node2 MountVolume.MountDevice failed for volume “pvc-d2be87db-ac99-45e7-9b77-79390a13d1eb” : kubernetes.io/csi: attacher.MountDevice failed to create newCsiDriverClient: driver name rook-ceph.rbd.csi.ceph.com not found in the list of registered CSI drivers
应该是配置卷没有找到,试着重新启动一下 rook-ceph-operator,重建配置看看能不能解决这个问题。但是我确实没有出现你们这种情况